Getting to Know Your Neighbors (KYN). Explaining ItemSimilarity in Nearest Neighbors Collaborative FilteringRecommendations
Joanna Misztal-Radecka and Bipin Indurkhya
misztalradecka@agh.edu.pl bipin.indurkhya@uj.edu.pl
https://doi.org/10.1145/3386392.3397599
The popular neighborhood-based Collaborative Filtering recommendation techniques are mostly characterized as black-box systems in which resulting outputs are not easy to interpret. In this work, our goal is to provide human-interpretable explanations of item-based collaborative filtering recommendations and the underlying data distribution. We propose the Know Your Neighbors (KYN) algorithm – a model-agnostic approach to explaining similarity-based CF recommendations on both local and global levels.
Motivation
A traditional way to explain the collaborative filtering recommendations [3] (we recommend X because you liked Y) does not provide an intuition about what makes the items similar. Hence, the main research question addressed by this work is: how to provide human-understandable explanations for neighborhood-based CF recommendations?
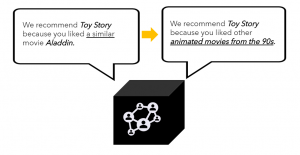
Proposed approach
The Know Your Neighbors approach provides:
- Model-agnostic explanations of the neighborhood-based collaborative recommendations,
- Local and global interpretability based on the descriptive item features.
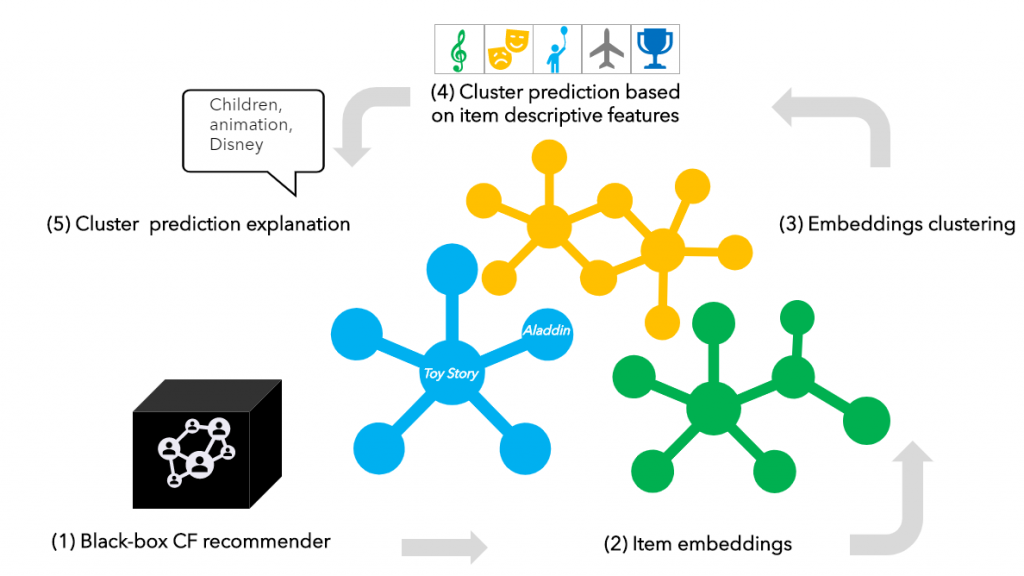
The KYN method (Figure 2) consists of the following stages:
- A Collaborative Filtering algorithm is trained to represent the latent behavioral patterns from the user-item interaction matrix.
- Item embeddings are extracted from the recommender latent representations.
- Unsupervised clustering is applied to construct item similarity clusters.
- The item-cluster assignment is used as labels and input to the proxy multi-class classifier with the descriptive item features as the input attributes.
- An explaining module provides the item similarity explanation based on the classifier predictions.
Experimental Setup
- Datasets: MovieLens (movies) and Deskdrop (articles),
- Collaborative Filtering representations: Item2Vec [1] and Non-Negative Matrix Factorization (NMF)
- Unsupervised clustering methods: k-Means, agglomerative clustering, HDBSCAN [2]
- Cluster prediction: logistic regression (LR), Gradient-Boosting Trees (GBT)
- Model explanation: SHAP [4]
- Visualization 2D: UMAP [5]
Evaluation tasks
Clustering quality evaluation
Metrics: Silhouette (close to 1 – perfect clustering), Davies-Bouldin Index (D-B Index) – (close to 0 for the best clustering)

- HDBSCAN gives the best clusters quality for NMF (both datasets) and Item2Vec (MovieLens).
- NMF representation gives a larger number of clusters with higher quality than Item2Vec.
- UMAP for embeddings dimensionality reduction improves the quality of the clusters.
Cluster prediction evaluation
Metrics: Balanced accuracy (ACC), Mathew’s Correlation Coefficient (MCC)

- GBT model performs better than LR (but the difference is not significant)
- Cluster prediction metrics are higher for Item2Vec (Deskdrop) and for NMF (MovieLens).
- The cluster prediction accuracy is high only if there is enough metadata to explain the collaborative space.
Qualitative analysis of neighborhood explanation
Local explanations for the neighborhood of movie Toy Story (MovieLens dataset):
- NMF — “children“, “cartoon“, “1990s“
- Item2Vec — “1990s“, “children“, “family“
Global explanations for Deskdrop dataset (most descriptive features):
- NMF — “Portuguese“, “English“, “Google“
- Item2Vec — “August“, “September“, “July“

- Item2Vec embeddings clusters are mostly described by the time dimension (year of production of publication dates) – possibly due to the sequential algorithm characteristics.
- For NMF representation other features are important (such as the item language or genre).
Results summary
- HDBSCAN with UMAP dimensionality reduction – the best clustering quality for most of the experimental settings.
- The analysis of neighborhood descriptions reveals possible algorithmic biases:
- Item2Vec: possible temporal trends and presentation biases related to highlighting the newest items,
- NMF: possible cultural biases (language separation)
Future Work
- Incorporating other types of descriptive features related to user and context.
- Experiments with different collaborative filtering algorithms (including deep learning approaches) on datasets from different domains to detect the possible biases they may be prone to.
References
- Oren Barkan and Noam Koenigstein. 2016. Item2Vec: Neural Item Embedding for Collaborative Filtering.CoRRabs/1603.04259 (2016). arXiv:1603.04259 http://arxiv.org/abs/1603.04259
- Ricardo J. G. B. Campello, Davoud Moulavi, and Joerg Sander. 2013. Density-Based Clustering Based on Hierarchical Density Estimates. In Advances in Knowledge Discovery and Data Mining, Jian Pei, Vincent S. Tseng, Longbing Cao, Hiroshi Motoda, and Guandong Xu (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg,160–172
- Yongfeng Zhang and Xu Chen. 2018. Explainable Recommendation: A Survey and New Perspectives. CoRRabs/1804.11192 (2018). arXiv:1804.11192 http://arxiv.org/abs/1804.11192
- Scott M Lundberg and Su-In Lee. 2017. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems 30, I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.). Curran Associates, Inc., 4765–4774. http://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions.pdf
- Leland McInnes, John Healy, and James Melville. 2018.UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv:stat.ML/1802.03426