Resources offered by information retrieval systems (IRS) must meet the reading abilities of their users if these resources are to be of value, i.e., relevant. Consider searching the Web for health information, in this case, readability is paramount for establishing resource relevance, especially if they include medico-scientific terminology. This example shines a light on readability as a major component of personalization. Yet, with readability assessment techniques being rarely portable across languages, the discussion around readability and personalization of multilingual IRS is relatively unexplored (Kelly et al., 2019).
Multilingual readability assessment: experimental set-up
Strategies for multilingual readability assessment tend to be limited to just operating in different languages rather than taking explicit advantage of the multilingual corpora they utilize. We present an in-depth empirical analysis we conducted to assess the language transfer capabilities of four different strategies for readability assessment with increasing multilingual power.
We conducted a number of experiments, each represented with a tuple of the form <𝑀, 𝐷, 𝐿𝑡𝑟𝑎𝑖𝑛, 𝑁, 𝐿𝑡𝑒𝑠𝑡>:
- M is a readability prediction model. We explored M1 based on a recurrent and hierarchical architecture, M2 (leveraging cross-lingual word embeddings), M3 (based on cross-lingual sentence embeddings), M4 (aggregates M2 and M3).
- D is a dataset. We used VikiWiki, which is a corpus comprised of simple/complex documents extracted from Vikipedia.org.
- Ltrain and Ltest, are the languages used from training and testing purposes, respectively. We considered Spanish, English, Catalan, Basque, French, and Italian.
- N is an ordered pair capturing the size of training and testing data.

Results
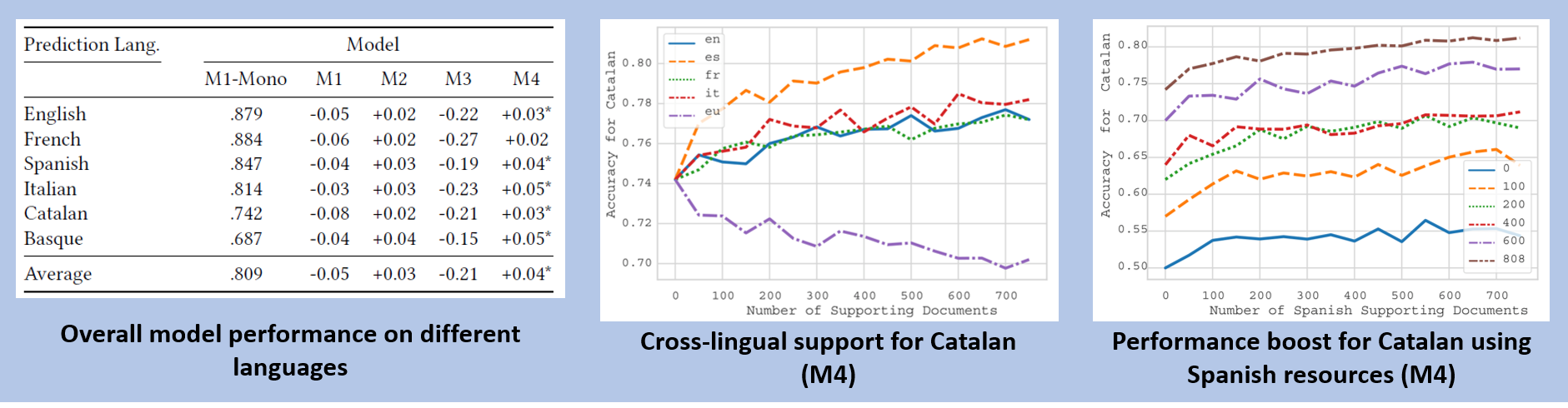
- Cross-lingual word embeddings and hybrid modes achieved the best improvements across all languages under study.
- Spanish is the language that best supports others; we attribute this to the typological similarity of Spanish with respect to other languages under study, like Italian.
- Basque does not help improve model performance when supporting counterpart languages (in fact, for Catalan, Basque resources lead to significantly decrease overall model performance), yet it is one of the languages that most benefit obtains from language transfer. This denotes a non-transitive relationship among languages when it comes to supporting for readability prediction.
- An important aspect of language transfer is that it can benefit minority languages, as resources for these languages tend to be scarce. For example, we see the benefits of using documents written in Spanish for training, regardless of the resource availability for Catalan — even in the zero-shot scenario where we use no Catalan resources at all readability prediction performance improves.
Lessons Learned
- Best transference characteristics are achieved by a hybrid model that combines both word and sentence level cross-lingual embeddings.
- The highest language transfer is observed among languages that are of similar nature, such as in the case of languages of the Romance family. Even in the case of typologically-isolated languages, transfer benefits occur, in terms of overall accuracy improvement.
- Further analysis is required to identify a multilingual readability assessment model that can support adaptation and personalization functionality of multilingual IRS, including:
- Exploring the use of sub-word level embeddings, as these could inform language transfer at the morphological level and as a result provide additional improvements for morphologically-rich languages, such as Basque or French.
- Expanding analysis by considering datasets with resources written in more languages and labeled with different readability levels, i.e., go beyond binary resource labeling.